What Makes Power Outages Last?
by Andre Gala-Garza (asgala@umich.edu)
Introduction
Power outages have consistently had negative impacts on the health of communities. Often, the severity of a particular outage is proportional to how long the outage lasts, since this increases the risk of food spoiling and water becoming contaminated. To alleviate these setbacks, a useful solution is to provide an estimate of how long an outage might last for, based on information that is known at the time of the outage. I aim to accomplish this goal during this investigation, where I will analyze a dataset of major power outage data in the continental U.S. from January 2000 to July 2016.
First, I will clean the dataset and conduct exploratory data analysis to obtain a basic understanding of the information the dataset provides. Next, I will explore the following motivating research question: What characteristics lead to power outages with longer durations? Specifically, I plan to use my exploratory analysis to reveal key relationships between the duration of a power outage and other features of a dataset, then create a model that predicts the duration of a specific outage given features of the outage that are known when it begins. This type of prediction would be essential for households and businesses to make preparations for outages that are proportional to their length, especially in dangerous situations such as hospitals, where the backup power for critical medical devices must be managed carefully.
The data used for this investigation was accessed from Purdue University’s Laboratory for Advancing Sustainable Critical Infrastructure. A data dictionary is available at the ScienceDirect article “Data on major power outage events in the continental U.S.”, under Table 1. Variable descriptions.
These are the features of the data which I will focus on in my investigation:
| Column | Description |
|---|---|
YEAR |
Indicates the year when the outage event occurred |
MONTH |
Indicates the month when the outage event occurred |
POSTAL.CODE |
Represents the postal code of the U.S. states |
NERC.REGION |
The North American Electric Reliability Corporation (NERC) regions involved in the outage event |
CLIMATE.REGION |
U.S. Climate regions as specified by National Centers for Environmental Information (nine climatically consistent regions) |
ANOMALY.LEVEL |
Oceanic El Niño/La Niña (ONI) index referring to cold and warm episodes by season, calculated as a 3-month running mean |
CLIMATE.CATEGORY |
Climate episodes corresponding to the years categorized as “Warm”, “Cold”, or “Normal” based on Oceanic Niño Index (ONI) |
CAUSE.CATEGORY |
Categories of all the events causing the major power outages |
OUTAGE.DURATION |
Duration of outage events (in minutes) |
DEMAND.LOSS.MW |
Amount of peak demand lost during an outage event (in Megawatts) |
CUSTOMERS.AFFECTED |
Number of customers affected by the power outage event |
TOTAL.PRICE |
Average monthly electricity price in the U.S. state (cents/kilowatt-hour) |
TOTAL.CUSTOMERS |
Annual number of total customers served in the U.S. state |
OUTAGE.START.DATE, OUTAGE.START.TIME |
Day and time of the year when the outage event started, as reported by the corresponding Utility in the region |
OUTAGE.RESTORATION.DATE, OUTAGE.RESTORATION.TIME |
Day and time of the year when power was restored to all customers, as reported by the corresponding Utility in the region |
Data Cleaning and Exploratory Data Analysis
Data Cleaning
The original data was saved as a Microsoft Excel spreadsheet, so I removed the first five rows, which were entirely blank aside from a general description of the data. I also removed the seventh row, which was only used to describe the units of some of the features. The sixth row was used as the header row. I also removed the first column, which was not part of the data itself.
There were a total of 1,534 power outage entries in the original dataset, which I loaded into a DataFrame using the Python library pandas. The DataFrame had 56 unique columns (features). In order to clean the data, I performed the following operations on the original DataFrame:
- Drop all unnecessary columns, leaving only the columns relevant to my investigation. These columns are:
YEAR,MONTH,POSTAL.CODE,NERC.REGION,CLIMATE.REGION,ANOMALY.LEVEL,CLIMATE.CATEGORY,OUTAGE.START.DATE,OUTAGE.START.TIME,OUTAGE.RESTORATION.DATE,OUTAGE.RESTORATION.TIME,CAUSE.CATEGORY,OUTAGE.DURATION,DEMAND.LOSS.MW,CUSTOMERS.AFFECTED,TOTAL.PRICE,TOTAL.CUSTOMERS. - Combine the date and time columns into Timestamp columns: I combined the columns
OUTAGE.START.DATEandOUTAGE.START.TIMEinto a single column,OUTAGE.START, in the format of a precise Timestamp. I did the same withOUTAGE.RESTORATION.DATEandOUTAGE.RESTORATION.TIME, combining them intoOUTAGE.RESTORATION. - In the columns for the severity metrics,
OUTAGE.DURATION,CUSTOMERS.AFFECTED, andDEMAND.LOSS.MW, I replaced any values of 0 withnp.nan, thus intentionally treating them as missing values. Logically, it is unreasonable for any of these metrics to have been actually measured as actually zero. Instead, zero was likely used as a placeholder for the true value of the variable, which is not present in the dataset. - Impute all
NaNvalues inTOTAL.PRICEwith the mean of the column. I describe this in more detail in the “Imputations” section of the investigation. - Remove all rows where
CLIMATE.REGIONis not applicable. There were only 6 rows where this was the case, and it was important to my investigation that values were present in this column. - Remove all rows where
OUTAGE.DURATIONis not applicable. There were 135 of these rows, which fell into one of two cases: TheOUTAGE.RESTORATIONvalue was either missing, or it was equivalent toOUTAGE.START, making the duration betweenOUTAGE.STARTandOUTAGE.RESTORATIONfunctionally non-existent. For both of these cases, since the focus of my investigation is theOUTAGE.DURATIONvariable, any imputation strategy would skew the outcome, so I felt that it was best to simply remove any entries where this column was missing.
Univariate Analysis
For my analysis, I begin by exploring some univariate relationships within individual columns of the dataset. First, I plot a bar graph of the number of power outages for each type of major cause of an outage:
Next, I plot a histogram of the distribution of outages by the total number of customers that were affected:
Interestingly, the distribution seems to be somewhat normal until the start of the bin with 6 million total customers, at which point the normality assumption can no longer reasonably hold.
I also plot the distribution of outages by the El Niño/La Niña anomaly level that was reported during the outage:
Bivariate Analysis
I continue with bivariate analyses to compare relationships between two variables. First, I draw a line plot of the average outage duration for each month in the dataset. Red lines correspond to odd-numbered years, while blue lines correspond to even-numbered years.
I then group the outages by the state in which they occured to produce a choropleth of the average outage duration by state:
This plot reveals that Wisconsin has the highest average outage duration, with New York and West Virginia following behind. Notably, many states with high outage durations on average are in either the Midwest or Northeast region of the United States.
Next, I make several scatter plots that compare outage duration with other variables in the dataset. First, I plot outage duration against two discrete features: the month in which an outage occurred and the major cause of an outage, respectively.
Next, I plot outage duration against two continuous features: the amount of peak demand (in Megawatts) lost during an outage and the El Niño/La Niña anomaly Level, respectively.
Based on aggregate information from the grouped tables seen below, I was also interested in the relationship between a state’s climate region and an outage’s duration. The following series of box plots show this relationship, revealing that East North Central and Northeast states seem to have longer outage durations on average, while West North Central states have very low duration outages.
Grouping and Aggregates
I constructed a table of the outages in the dataset grouped by CLIMATE.REGION and performed the aggregate function mean(), in order to find the average severity metrics for each region. Here are all of the rows in the grouped table:
| CLIMATE.REGION | OUTAGE_DURATION_MEAN | CUSTOMERS_AFFECTED_MEAN | DEMAND_LOSS_MW_MEAN |
|---|---|---|---|
| Central | 2882.21 | 144424 | 595.682 |
| East North Central | 5391.4 | 149816 | 633.902 |
| Northeast | 3330.52 | 177848 | 1013.4 |
| Northwest | 1536.36 | 136768 | 336.036 |
| South | 2872.45 | 212031 | 475.686 |
| Southeast | 2247.66 | 202705 | 865.318 |
| Southwest | 1621.41 | 66121.1 | 903.25 |
| West | 1636.31 | 217946 | 711.566 |
| West North Central | 796.071 | 66242.4 | 251.333 |
I also followed a similar procedure for the column NERC.REGION, to find the average severity metrics for each North American Electric Reliability Corporation (NERC) region. Here are all of the rows in the grouped table:
| NERC.REGION | OUTAGE_DURATION_MEAN | CUSTOMERS_AFFECTED_MEAN | DEMAND_LOSS_MW_MEAN |
|---|---|---|---|
| ECAR | 5603.31 | 260624 | 1394.48 |
| FRCC | 4271.12 | 385068 | 1108 |
| FRCC, SERC | 372 | nan | nan |
| MRO | 3001.81 | 107524 | 281.429 |
| NPCC | 3578.65 | 164358 | 1695.22 |
| RFC | 3767.79 | 157057 | 429.434 |
| SERC | 1765.29 | 117203 | 608.125 |
| SPP | 2783.57 | 231177 | 192.118 |
| TRE | 2988.24 | 253805 | 739.093 |
| WECC | 1578.27 | 182706 | 664.74 |
Imputations
In the column TOTAL.PRICE, which indicates the average monthly electricity price in the U.S. state corresponding to a certain outage, a total of 22 values were missing (NaN). I considered these values to be missing completely at random (MCAR), due to the small number of these outages and their varying indices from across the original dataset. Since the distribution of the column appeared relatively normal, I felt that these missing values would be representative of the dataset as a whole. Therefore, I chose to use mean imputation on these values by replacing them with the mean TOTAL.PRICE for all outages.
This is what the distribution of TOTAL.PRICE looked like before imputation:
As there were only 22 missing values, the distribution appeared relatively unchanged after imputation:
Framing a Prediction Problem
My prediction problem is to predict the duration of a power outage; therefore, the response variable is OUTAGE.DURATION. This is a regression problem, since the model will predict the continuous quantity of how long a power outage lasts. I chose this response variable because when a household has a power outage, having an estimate of the time taken before recovery is crucial for making decisions such as whether to use a backup generator or continue storing perishable food.
The time of prediction would be immediately at the start of a power outage. Therefore, at prediction time, the following variables from the original dataset would be known: OUTAGE.START.DATE, OUTAGE.START.TIME, YEAR, MONTH, POSTAL.CODE, NERC.REGION, CLIMATE.REGION, ANOMALY.LEVEL, CAUSE.CATEGORY, CAUSE.CATEGORY.DETAIL, TOTAL.PRICE, TOTAL.CUSTOMERS.
Clearly, variables such as OUTAGE.RESTORATION.DATE and OUTAGE.RESTORATION.TIME are outcome variables not available at the start of an outage.
Regional economic and land-use characteristics from the original dataset, such as PC.REALGSP.STATE or POPULATION, are aggregated at a regional or state level, and thus do not provide specific information about the infrastructure or condition at the exact location of an outage. Therefore, I chose to exclude these variables from my model.
For my regression model, I will use the performance metric of root mean squared error (RMSE):
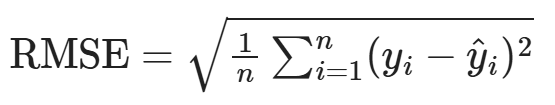
I chose this metric because it is similar to the mean squared error (MSE), which penalizes larger errors more than smaller ones due to the squaring term. This makes it a better metric than mean absolute error (MAE), because incorrect predictions can have critical consequences in this case. For example, significantly underestimating a long outage may cause a family in a household with said outage to keep food in their refrigerator only for said food to perish. However, I also wanted to balance the sensitivity to large errors with immediate interpretability. Since RMSE produces a prediction with the same units as the response variable (in this case, the number of hours for which a duration lasts), it is ideal for my model.
I will additionally use the R^2 metric:
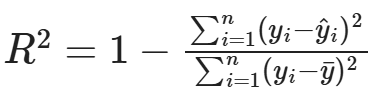
This helps compare the predictive power of my baseline model with my final model, which adds more features to use for predictions.
Baseline Model
My baseline model predicts the duration of an outage using features that are straightforward, immediately available, and broadly applicable across all outages.
The features I used in the baseline model are as follows: MONTH, ANOMALY.LEVEL, POSTAL.CODE, CAUSE.CATEGORY, CLIMATE.REGION.
MONTH(ordinal) is useful for identifying temporal or seasonal patterns in outages, and unlikeYEAR, it is generalizable to future dates and is not too broad of a duration in between measurements.ANOMALY.LEVEL(quantitative) captures El Niño/La Niña anomalies, which could impact weather-related outage durations. This is especially useful for extreme or weather-sensitive scenarios, which helps account for the outliers in the data set.POSTAL.CODE(nominal) provides geographic specificity that can account for localized infrastructure or response capabilities.CAUSE.CATEGORY(nominal) captures high-level reasons for outages, which are directly linked to their expected durations (e.g., equipment failure vs. severe weather).
In this model, the quantiles for numerical features (MONTH, ANOMALY.LEVEL) are reduced to 500, which is ensured to be below the number of samples in the dataset. Meanwhile, categorical features (POSTAL.CODE, CAUSE.CATEGORY) are encoded using OneHotEncoder to convert nominal categories into dummy variables.
The RMSE of the baseline model is 6426.33, and its R^2 value is 0.133345. Here is a line plot comparing the baseline model’s predictions for outage durations and the actual durations:
The line for the baseline model’s predictions (in orange) deviates significantly from the actual durations (in blue). Therefore, we can conclude that the baseline model will generalize rather poorly to unseen data.
Final Model
My final model includes additional features that offer finer granularity to improve predictive accuracy.
The features I used in the final model are as follows: MONTH, ANOMALY.LEVEL, POSTAL.CODE, CAUSE.CATEGORY, CLIMATE.REGION, NERC.REGION, TOTAL.PRICE, TOTAL.CUSTOMERS.
Here is an explanation of why I added the new features to the final model:
CLIMATE.REGION(nominal) represents regional weather characteristics that influence the duration of outages (e.g., storms in the Southeast vs. snowstorms in the Midwest).NERC.REGION(nominal) represents reliability regions, reflecting differences in grid infrastructure and operational capabilities.TOTAL.PRICE(quantitative) indicates the cost of electricity, which may correlate with infrastructure investment levels or restoration priorities.TOTAL.CUSTOMERS(quantitative) reflects the scale of the outage and could relate to the resources allocated for restoration.
The modeling algorithm I chose was RandomForestRegressor. This was very useful for my purposes, since the RandomForestRegressor can predict a continuous target variable by averaging the outputs of multiple decision trees. It handles both numerical and categorical variables and can perform well even when capturing non-linear relationships or interactions between features. Finally, its averaging mechanism across multiple trees reduces the risk of overfitting compared to individual decision trees.
Within my sklearn Pipeline, I also create two new features:
- I use a
Normalizerto normalize values ofANOMALY.LEVELto the unit norm. This creates a variable that consists of the positive and negative signs associated with the anomaly level of each outage. - I use a
Binarizerthat evaluates to 1 ifTOTAL.CUSTOMERSis 6 million or greater, and 0 otherwise. This separates outages into two groups: one has a relatively normal distribution forTOTAL.CUSTOMERS, and the other does not.
GridSearchCV performs an exhaustive search over the specified parameter grid to optimize RandomForestRegressor parameters, such as:
n_estimators: Number of trees (100 or 200).max_depth: Maximum depth of the trees (10, 20, or None).min_samples_split: Minimum samples required to split an internal node (2 or 5).min_samples_leaf: Minimum samples required in a leaf node. (1 or 2).
These were the hyperparameters that ended up performing the best: n_estimators = 100, max_depth = None, min_samples_split = 5, min_samples_leaf = 2.
The RMSE of the final model evaluated to 6307.16, and its R^2 value is 0.165188. This is an improvement from the baseline model’s RMSE and R^2 of 6426.33 and 0.133345, respectively, since RMSE should be minimized and R^2 should be maximized.
Here is a line plot comparing the final model’s predictions for outage durations and the actual durations:
This line plot compares both models against each other, along with the actual durations:
From the above graph, we can see that the final model’s prediction for outage durations (in green) matches the actual durations (in blue) quite closely, when taking into account the large fluctuations made by the outage duration over time. Therefore, we can conclude that the final model will generalize relatively well to unseen data.